As promised, I’ve got some information about the project to recalibrate our K constant today. K is a parameter in the Elo rating system that determines how many points each match is worth. Right now ours is set to K=36, which means that the two participants in a match bring 36 points to the table for each match. If the players have exactly the same rating, then both players “ante up” 18 points. Otherwise the higher-rated player will risk some P (greater than 18) of their points on the match, with the lower-rated player contributing 36 - P points of theirs. As K increases, each match is worth more points, so the ratings become more volatile. This causes there to be less information in the ratings, since the effects of matches from long ago are drowned out when every match is causing a big swing. With the current value of K, the ratings stop being sensitive to a single old match after about 45 matches, and the effect of an entire tournament is blunted once we reach about 125 matches.
In short, my plan for recalibrating K was to adjust the value of the constant, rate everyone, and then go back and examine everyone’s ratings at the time of each of their matches. The Elo formula predicts certain values for those win percentages, like the higher-rated player should win 60% of the time if the ratings disparity is exactly 200 points. So we should try to pick the rating scheme that causes the data to best fit the model: this maximizes the meaning that the ratings have.
I tried a bunch of different constants and a couple of different rating schemes. The results are summarized in this Google spreadsheet. I encourage you to take look at some of the alternative models that I examined there. Here’s a look at how the current system (every match is K=36) is doing.
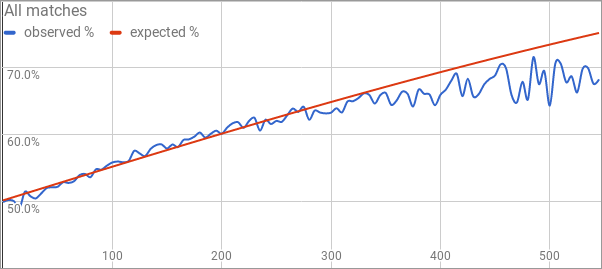
The horizontal axis is the rating discrepancy between the two participants in a match, with the win percentage of the higher-rated player on the vertical axis. Honestly, of all the rating schemes, this one seems to do the best when it takes every match into consideration. This shouldn’t be too amazing; I chose K=36 at the beginning of the project because it seemed like the best choice for K at the time. Keep in mind that there are very few matches between players that have a 400+-point rating disparity, so the tail begins to wobble due to the effects of a small sample size.
Here’s my concern. This is the same graph again, but where instead of looking at every match, we only look at matches between people who have already completed 25 matches. Your rating isn’t necessarily correct at first, so this gives people a “provisional period” to get closer to their actual rating before we start counting their matches as being useful data toward the calibration process.
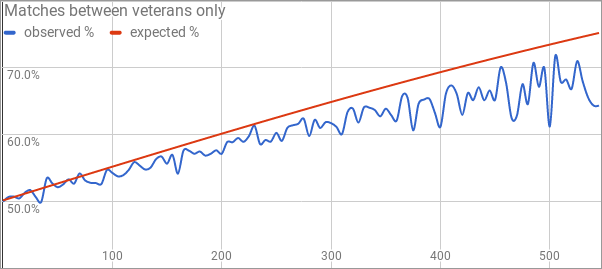
In these matches between “veterans” we’re consistently falling short of the target line. This is what initially made me say a few months ago that K=36 is too large. It leads to people achieving ratings higher than they’re “supposed” to have, and so the higher-rated player loses more often than Elo is predicting. This undershooting effect is less pronounced with K=27 or K=30, as you can see on the spreadsheet.
This probably should lead you to propose a system where matches between veterans are played at a lower K than matches where one of the participants still has a “provisional” rating. I examined those sorts of rating schemes in the spreadsheet too. Do any of them look appreciably better than the pictures in this blog post of a flat K=36? Maybe a K=36 / veterans at K=27 split is a tiny bit better, but I don’t think it’s a big enough improvement to warrant a switch.
Also I should point out here that making matches between veterans have a lower K-value does something very counterintuitive: it nerfs the impact of Pro Tour events, where essentially everyone is a veteran. This is the opposite of how most people seem to think it should go — in fact I’ve had multiple people tell me that it’s blasphemous that we’re not using a higher value of K for Pro Tour events! It is true that in the old DCI rating scheme, Pro Tours had a value of K that was 1.2 times the value of K for Grand Prix. But the DCI rating scheme was also supposed to be a world ranking of sorts. It needed to be built into the system that winning the Pro Tour would be a guaranteed massive boost to your rating. The Elo project is, as we’ve said, for entertainment purposes only, so I don’t lose sleep at night over this. There is an effect that increases the value of a deep run at a Pro Tour: the average rating in the room is much higher, so you see many more matches worth 18 points to each player and fewer of the 6/30 variety. For a player with a high rating, a Pro Tour is the best chance to push their rating up even higher. (It seems that once you reach a rating of around 2100, going 8-4 at a GP — that is, 11-4 with three byes — might not even be enough to tread water. On the other hand many people in the same range made some progress at PT Amonkhet going 11-5 or 10-6.)
As K varies, all of the different rating schemes have trouble at the high end, independent of the small sample size issues. The underlying shape each graph wants to make has more of a bend to it than the red graph has. I think this reflects the fact that win percentages over 70% aren’t seen at this level of play. Less than thirty people who have played 200 matches have a 65% lifetime win percentage. So it’s possible that the right way to improve the ratings on the site is to change the Elo model itself by lessening the expectation once we get over a 300 point disparity or so.
Let me offer a counterargument to the previous paragraph. (This either goes to show that I’ve thought about this all too much or that it’s a really complicated problem.) Most of the matches with really large rating disparity involve someone who’s been on a heater and has a 2000+ rating playing against someone with a rating in the 1500-1600 range. A 1600 rated player is still pretty good; that’s someone who’s at or slightly above .500 in their premier play career. I think we’d expect to see a better performance from the higher-rated player in matches with a huge disparity if we could get some matches between, like, 1700s and 1200s. But these by and large do not exist! There are two reasons: (1) people with 1700+ ratings typically have two byes, and so avoid a lot of the weaker players who have no byes, and (2) people whose actual skill would lead them to have a rating of 1200 or below tend not to play enough matches to reach their actual rating in the first place, because there’s no incentive to stay in the tournament after you’ve lost a bunch. For a player like Owen Turtenwald who deserves a rating in the 2000s which means “I 11-4 every GP,” he’ll naturally arrive at that rating by 11-4’ing every GP. But if you deserve a rating that says “I basically 2-7 every day one,” getting the total number of matches needed to arrive in the ballpark of that rating is very difficult.
This was a 1250-word way of saying that I’m not going to make any adjustments at the moment. There are two other factors that have to get weighed against making any changes: continuity and simplicity. I’d prefer not to change the scale in such a way that old blog posts, graphics, Reddit threads, etc., stop corresponding to what’s on the site. And I’d also prefer for the rating system to be something that can be explained in one paragraph, if a two-paragraph or five-page mathematics paper version doesn’t seem to lead to any real improvement. This isn’t to say I’m done looking for better options (the idea of tweaking the underlying model is intriguing!) but for now it’s back to the curating process for 2008-09.
You may be able to infer from this blog post that I could talk about this endlessly; if so you would be correct. I’d love to hear any thoughts or suggestions you might have about this topic! Send them to mtgeloproject at gmail dot com.