Let me start by apologizing for taking so long to write this—I think I’ve blocked out time for this update close to ten times in the last few months and usually I’ve elected to prioritize getting work done over writing about what I’ve been up to. Following the broad outline suggested in the previous post, let’s talk about curating today; this is the stage of Elo 2.0 that required the most person-hours and happily is now all done, and the web development stages are going on in the background. We aim to have the site operational soon. Likely we won’t have 100% of the bells and whistles on launch; for example we’re going to re-do how the graphs are drawn, but that’s a modular thing that isn’t tied to the site being functional. I also have toyed with the idea of changing the Elo formula in some way, possibly using Glicko2 or something with more knobs to turn, but I expect the current rating system will be in place when the site re-launches.
The incoming update will cover approximately 650 tournaments and around 950,000 matches. This includes the following events:
- Every SCG Invitational, Player’s Championship, and individual event in the Open Series. There are approximately 13 Opens from 2012-13 that didn’t have preserved usable data that I had to skip. Several events had other sorts of data issues that I tried to patch as well as I could. Several times in the era where there was a Saturday standard Open followed by a Sunday legacy Open, a couple of the standard files were overwritten on Sunday by legacy. This necessitated reconstruction via tiebreakers. There were a few other reconstructions based on exactly what data survived. Almost always this was limited to one round here or there. Events with two or more rounds missing I probably gave up on.
- Every national championship for which there’s preserved data, plus apac00, apac01, latam00, and latam01. There’s a schematic that shows what data exists in the previous blog post; since then I found Australia 2002 and 2003, but that’s all that I’m aware of.
- Every PTQ held at a MagicCon in 2023-24 (both the Friday and Saturday open-to-the-public ones and the Sunday rebound PTQ for PT participants).
- Many two-day “destination RCQs”, including every Legacy EU Grand Open Qualifer, every two-day SCGCON RCQ, and every Laughing Dragon MXP two-day 20K. There’s more to do here, but I’m going to worry about continuing to fill out this part of the database (the “2022-present GP substitues”) after the site is launched. If you have suggestions about other things that belong in here, don’t hesitate to suggest them. This will be the focus of a future post and considerable Twitter activity once the site is finished.
- This probably goes without saying but the missing Regional Championships from the first half of 2024, as well as PTMKM and PTOTJ, were curated as part of this batch of tournaments as well.
- I also curated the Secret Lair Showdowns from the MagicCons that have happened already; this is a controversial topic, where the silent majority thinks they shouldn’t be added but anyone who bothered to voice their opinion were unanimously on the side of including them. I did it because I was curious to assess the strength of the field, and I thought that there would be reasonable overlap with people playing both these and PTQs, so curating them together would save me time. We can open this can of worms more fully in that future post.
A large part of the challenge in turning all this data into something usable on the site stems from the fact that what’s on the site presently does not exactly match the unrefined state in which I found the data in the first place. Many names change slightly from event to event; not necessarily as extremely as Paulo Vitor Damo da Rosa, but still, there are untold numbers of Mike vs. Michael, Steve vs. Stephen, etc. that needed to be fixed. Worse, in the 2013-2016 era (literally the heyday of the SCG Tour) the version of the software used for running large events defaulted to including everyone’s middle initial. This means even names which don’t have any obvious variants usually have at least two different versions. I made the decision that if [UniqueName, Collin Q] showed up during this era but in new events they appear as [UniqueName, Collin], then I should just drop the Q because my ingestion process would automatically link the two names if they matched.
However we’re now going back and adding new information from the past, and it would be nice if I could just reach back into our history and ask “what raw names came together to form this entry?” In principle if the computer could answer this question, then I could match the old raw name [UniqueName, Collin Q] against the incoming SCG data and automatically curate it to drop the Q and match the current version of the name on the site. Uh, yeah. So this is where I admit that I didn’t see a need to save the original raw data, because (a) I assumed it would be available should I need it in the future and (b) we didn’t build the site with intention of scaling it this way, so this curating task wasn’t something I prepared for.
Obviously we got whammied on both fronts here, in that almost everything that was once on the internet only exists on the Wayback Machine, and now we need it. To be fair to past Adam, I did save the final standings for every event that’s on the site, which has served me well as a proxy for the raw data. (Hold this thought because we’re going to come back to final standings soon.) But some curated names look dramatically different from the raw versions—think about people transitioning and going by something that looks nothing like their deadname—so it would be somewhere between nontrivial and impossible to cross-reference a curated name against the final standings and expect to get a match every time. If instead I had the actual raw pairings, then there would be a marker for the cross-referencing, since then I could look up the winner of round 3, table 141 in both the raw and curated databases and establish a link that way.
Thankfully some of the heavier lifting has been done for me: the ormos archive has grabbed and standardized some of what’s been archived under wizards.com. The project is more concerned with building a complete text archive of the articles that once appeared on the mothership, but their crawlers did pick up just about everything from the last generation of the event coverage archive before it was repalced with magic.gg; that covers data from 2014-2018 or so. I used this to create a complete raw round-by-round document for approximately 200 events before I hit a wall.
Some issues I encountered were there the first time I worked with the data, like the rounds whose results were all listed as “pending.” This happens if the event software rolls over to round N+1 before it generates the results document for round N. Since apparently the software could only generate the current round’s results, what gets produced in this situation is the round N+1 pairings, with no results available (hence “pending”).
Other issues I encountered were new from the first time I worked with this data, because 2016-17 was when we first made the site and so these were the earliest events that I worked with. It didn’t occur to me until a little later on that the raw data could lie to me, at which point I started doing accuracy checks. Maybe “lie” is a strong word, but it’s possible for the results to say A won over B in a match and have that not be what actually happened. Here again the issue is that the score reporter only moves forward in time; once the pairings/results/standings for round N are created, those documents are static and effecitvely immutable. So if the players filled out the match slip backwards, or the scorekeeper entered the result into the system backwards, the fix for that is to manually adjust the two players’ match points and re-pair them against players of the appropriate record, but at no point will anyone go back to the results page and flip what’s reported there. So as part of generating the raw versions of each event, I tabulated [3reported wins + 1reported draws] for each player, and compared that match point total against what the final standings said they should have earned. If there was a discrepancy then I reversed matches as needed. There also were frequent issues (possibly stemming from late registration or something?) where some players who had byes were not correctly entered into the tournament with byes, and consequently would get paired round 1, lose, get dropped from the tournament as a no-show, and then re-appear in round 3 or 4. I cleaned up every instance of this that appeared in the events that I re-curated. Sometimes the “fix” for people getting dropped for having the wrong number of byes was to put them into the tournament again as a separate entry, in which case their name appears twice in the final standings (once with 0 match points and once with nonzero). I destroyed those second copies. I also separated any “doubleplays,” that is, two players with the same name who played in the same round. There are still some from pre-2014 that need to be separated, but none are left in either the new data or the events for which I generated raws.
As I worked my way back to mid-2015, things started getting weird: the names in the pairings no longer reliably matched the names in the final standings. This was the wall I told you I hit, at which point gathering more GP raws was more trouble than it was worth. It got pretty bad, with over 50% of the names slightly different. Even weirder, some players were just completely missing. Here’s the archived final standings for GP London 2015. Who finished 193rd?
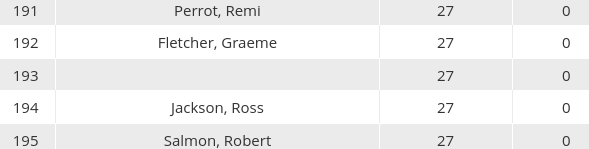
I was able to figure this out, but what the heck? Sometimes filling in the blanks was as easy as cross-referencing round 15 standings; sometimes I needed to look at tiebreakers in order to sort the possible suspects. And remember this wasn’t as easy as just “line up pairings and standings, look at the 8 missing people, and pick the one with 27MP” because hundreds of players in the pairings don’t have an exact match in the standings. Usually this was an due to a missing middle initial or other minor inconvenience, but there were some players in the pairings that I could only line up with the standings after calculating tiebreakers in order to figure out where someone with their results actually belonged. Sometimes the issue stemmed from a player going by their middle name either in the standings or in the pairings (eg. [UniqueName, Collin Q] appeared in all the pairings that way and then showed up in the final standings as [UniqueName, Quincy]); this led to the discovery that pages and pages of players were actually the same entity (oh, [UniqueName, Quincy] played in Stockholm 2016, huh?). My best guess is that the names in the pairings were the names given to the tournament organizer when the player signed up for the event, while the final standings with money and pro points were generated by Wizards a few days after the event, and they used the names in the DCI database. The blanks are from people who typoed their DCI number or something, in which case when Wizards looked them up they got an IndexError, or even worse some other unrelated person.
Ultimately this task of acquiring raws was not directly contributing to getting new data on the site, so I stopped working on it when it became too arduous. But it did let me do the task that I wanted for it; anyone who appeared in an uncurated new event with a name that matched a player in a raw event was auto-curated to the corresponding version of their name in the curated database. I should also add here that I have learned my lesson and have done a better job of keeping verisons of new events at different points in the life cycle, should that prove useful down the road curating future events. I learn these things the hard way, but I do learn!
Most of the rest of the curating process looked pretty similar to what had been doing. I went with a fine-toothed comb through every name in the SCG Invitationals and all the national championships to try to get them as close to correct as I could. For other rank-and-file additions I looked for things like “is anyone one character off from someone else?” (possible typo), or “is a new name a substring / close to a substring of a current name?” (possible nickname, middle initial). I did what I could to try to get the data as accurate as possible, but obviously once the new data is ready you should definitely check your history, get your friends to check their history, etc., because I’m sure there’s a lot I got wrong. When I started there were 45,093 names in the new events that didn’t match anyone in the database; by the end of curating that was down to 25,458. So I did something.
Some of the background processes were re-coded because I took this opportunity to rearrange the underlying data structures. As one example, with Elo 1.0 we were expecting every event to either start “gp-” or “pt-” and as such the events were just a big list in chronological order. If I wanted to see PTs, I could just filter out those events whose codes didn’t start with “gp-”. This obviously wouldn’t fly any more, so I made a separate database for events that knows things like date, format, tournament series (gp, pt, scg_open, rc, etc.), URL to archived data. This means we’ll be able to provide a list of links to old coverage again, replacing the lost coverage archive on Wizards site. The tournament series codes are there so that you can filter someone’s match history to see only the SCGs, or tell the leaderboard page you only care about records in PTs. This upgrade will also make it possible for me to add events into the middle of the chronology significantly more easily, so if we find data for some of the missing SCGs or if anyone wants to give me the final standings for PT New York 1998 (hint hint) it’ll be significantly easier to stitch it into the middle of the database.
I admit talking about new site functionality makes me want to stop writing this and get back to actually coding some of it, so I’m going to stop here for today. Next time (possibly concurrent with the site launching) I’ll write a bit about what we’ve done to modernize the site frontend and accommodate the new data. Cheers!